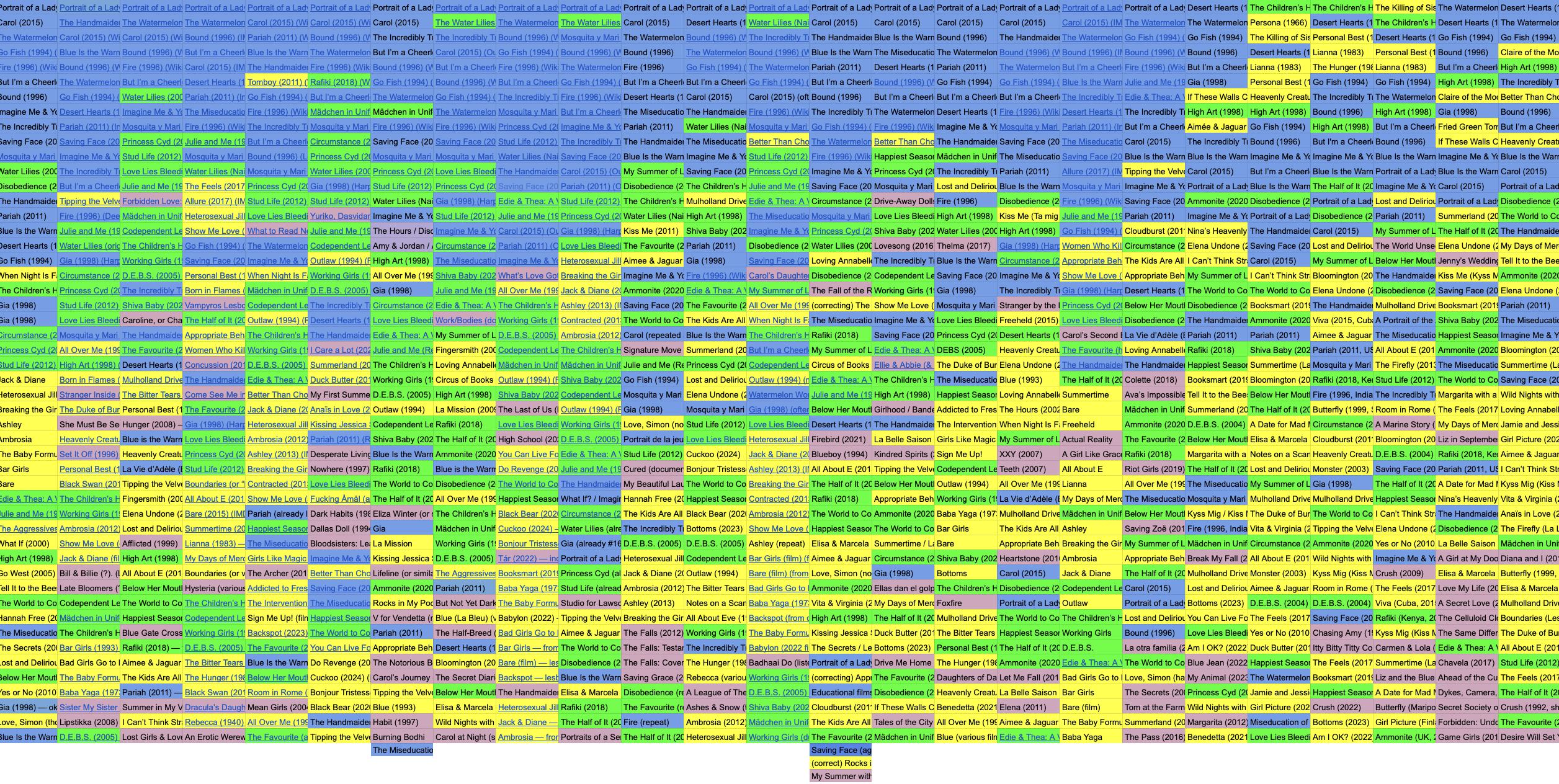
As AI-generated media content becomes ubiquitous, I began to wonder how GenAI models might influence Lesbian representation in future cultural artifacts. To assess this, I designed an audit experiment to observe how ChatGPT retrieves and remixes data from existing Lesbian films. I worked with two models, Dall-E 3 and ChatGPT-5's integrated image generator. Both models are accessible in the basic paid version of ChatGPT. Following the basic tenets of auditing — "repeatedly and systematically querying an algorithm with inputs and observing the corresponding outputs in order to draw inferences about its opaque inner workings" (Metaxa et al) — I prompted ChatGPT-5 to create a list of 50 Lesbian films. I asked the same question 25 times in individual, separate chats. In a dataset of 1256 film titles (sometimes I received more than 50 in a list), 17 films received over 20 mentions.
When the model ventured to pull titles from the deeper well of queer screen presentations, Lesbian subplots made the cut, subtext alone was deemed good enough, too, and baffling single mentions found their way into the dataset. One of my favorite inclusions was "The Fall of the Roman Empire (fictional) — just kidding, that's not one," which the model pulled from Reddit, including the annotation.
Working further with the 17 most-mentioned film titles, I played a game of algorithmic telephone, creating a chain of prompts. I first asked each model to generate stills "inspired by the Lesbian film [title]" and observed that, by and large, the model initially preserved and exaggerated aspects of cultural context and retained the racial identity of the protagonists, while depictions of gender identity moved them toward a more feminine, younger look.
How the models revised my sparse prompt — which aspects did they fill in, which did they ignore — and how they arrived at the images and stills they produced became part of the analysis. By excerpting the revised prompt (for Dall-E) or asking the model how it revised the prompt (for GPT-5), I was able to compare two corpora of image descriptions, finding that both models relied on more detailed background or lighting descriptions to attempt emotional resonance and tone, shifting away from the expressive potential of a human face or body.
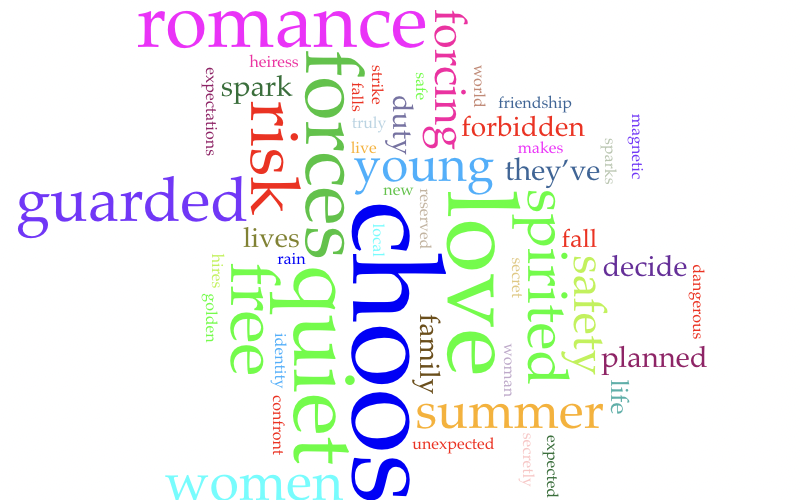
I then asked the models to generate a logline (a one to two-sentence essential summary of the film) from the stills. Comparing the generated loglines to the loglines excerpted from IMDb, I noticed a pronounced shift in language. The word "Lesbian" had disappeared from loglines, and other nouns signifying identity receded in favor of vague formulations of a movie's central dilemma, which places protagonists in a position to "choose between being true to themselves" and (some version of) complying with external demands. Ostensibly, these loglines still hint at queer stories, but they no longer use clear language to name themselves as queer stories, thereby producing a new ambiguity.
Based on these loglines, I then prompted the models to create film posters including new titles. In my request, I specifically asked for posters for Lesbian films. The resulting poster set shows evidence of an aesthetic center of gravity reminiscent of mass-market romance. The loss of variety, both aesthetically and verbally, is staggering. All titles bearing character names have been replaced with combinations of prepositions and weather conditions or nondescript locations. And so Carol transforms into Through the Rain, and Pariah morphs into Bedroom Sonnets. Aesthetically, the default posters the models generated reminded me of cheap paperback covers. Not a single version generated by GPT-5 offered a more experimental composition.
But the system's inner workings are also revealed in its glitches. In my requests for Lesbian film posters, GPT-5 proposed broken pixel collages that left visible the essential building blocks of its standard compositions and the seeds of its homogenizing approach.
Throughout the experiment, I had carefully maintained the word "Lesbian" in my generation requests. Perhaps I intuited the compulsive heterosexuality of the default? This is why, in the two final rounds of my experiment, I tested the model's response by again requesting stills based on its loglines, this time omitting "Lesbian": GPT-5 turned one third of the films into straight stories, left a few ambiguous, and retained only those that clearly used terms like "two women" in the logline as potentially queer.
Finally, I asked it to create posters based on the film titles it had generated previously, and again I omitted the "Lesbian" from my request: all 17 posters turned un-queer and more racially homogeneous. Not a Lesbian trace was left.
And while the flattening of identity and representation is most obvious when we look at the AI-generated images in aggregate, a closer reading of the outputs collected for a few titles highlights the intersectional dynamics of erasure. In Saving Face's poster series, we can observe the data journey beginning with a complex relationship featuring Chinese American protagonists and ending with a straight white couple.
The erasures and omissions are what's interesting. The model doesn't know what it doesn't know and has no sense of what it fails to produce. The homogeneity the algorithm continually manufactures becomes the de facto representation, and when the possibility of Queerness has to share algorithmically generated outcomes with the algorithms' defaults, Queerness and Lesbians disappear from the cultural landscape.
Three Degrees of Representation aims to chart how the algorithm's compulsively conservative/un-queer defaults work to reentrench a norm that sees variety as deviant.