More Sentences, Please: Image Description Analysis
How GenAI expands sparse prompts into detailed image descriptions
As part of the experiment, I asked two related/integrated models to generate images inspired by the titles of the 17 most frequently appearing films in the Lesbian film dataset, which was also assembled by GenAI. I asked Dall-E to "Create an image inspired by the Lesbian film [title]." I knew from experience that this model would interpret image as a synonym for a still image, while GPT-5 would interpret "image" in a variety of styles, and frequently provide an output it qualified as oil painting. In order to manage the discrepancy outputs, I asked GPT-5: "Create a still inspired by the Lesbian film [title]."
Then, to ascertain how Dall-E and GPT-5 expanded upon the sparse prompt I provided, I collected Dall-E's grounding (the full prompt the model devised and used to render the requested image), which is provided alongside the image. For the images made by GPT-5, I asked, "Can you share how you adapted the prompt for this image?" and then collected a portion of the answer that provided a revised prompt. GPT-5 also often added additional parameters, like deliberately excluded parameters, e.g., "No logos, no identifiable public figures."
An Example: Desert Hearts
For example, the prompts for an image or still inspired by the Lesbian film Desert Hearts were revised as follows:
Dall-E:
A romantic and cinematic desert landscape inspired by the 1980s lesbian film 'Desert Hearts'. Two women stand close together in an intimate moment near a rustic motel, with vintage 1950s cars parked nearby. The scene captures a tender sunset glow casting warm tones over the Nevada desert. One woman has short dark hair and wears a retro 1950s-style shirt and trousers, while the other has blonde wavy hair in a vintage dress. Their body language is emotional and affectionate, reflecting a blossoming romance. The background includes red rock formations, desert brush, and a lonely highway leading into the horizon.
GPT-5:
This film photograph depicts two women in soft desert twilight, exchanging glances as the golden glow from the setting sun bathes them near a motel pool. One woman wears a light blue sundress, the other a cream blouse and beige trousers; both are framed by the vintage, neon-lit "Desert Inn" sign and the distant mountains, with muted pastels and warm tones that capture a nostalgic, serene mood.
To me, most striking in these examples and in the respective corpora overall is which aspects are described in detail and which are not described at all. That the women are young and white in this inspired still description seems to be assumed, while in films with POC protagonists, race and skin tone are described. Also noteworthy is the detailed focus on background and colors, dress and hair, as opposed to say, facial expressions. The emotional resonance of an image is often outsourced to the background and its atmosphere-creating color spectrum.
Dall-E's Image Descriptions
The models' priorities in generating images and image descriptions become even more apparent when we examine the most prevalent words in the corpora of collected descriptions from both models.

A word cloud showing Dall-E's most frequently occurring terms in the image description corpus.
In addition to words qualifying the resonance the image is aiming for ("emotional," "intimate," and "scene"), "hair" and associated attributes, as well as terms further defining clothing and "background" are most prominent.

A word tree showing Dall-E's occurrences and collocates of "hair" in the image description corpus.
GPT-5's Image Descriptions
As is discernible in the visualizations below, the image description shared by GPT-5 emphasizes adjectives like "warm," "soft," and "golden," focusing on achieving a homogeneously "warm" atmosphere.
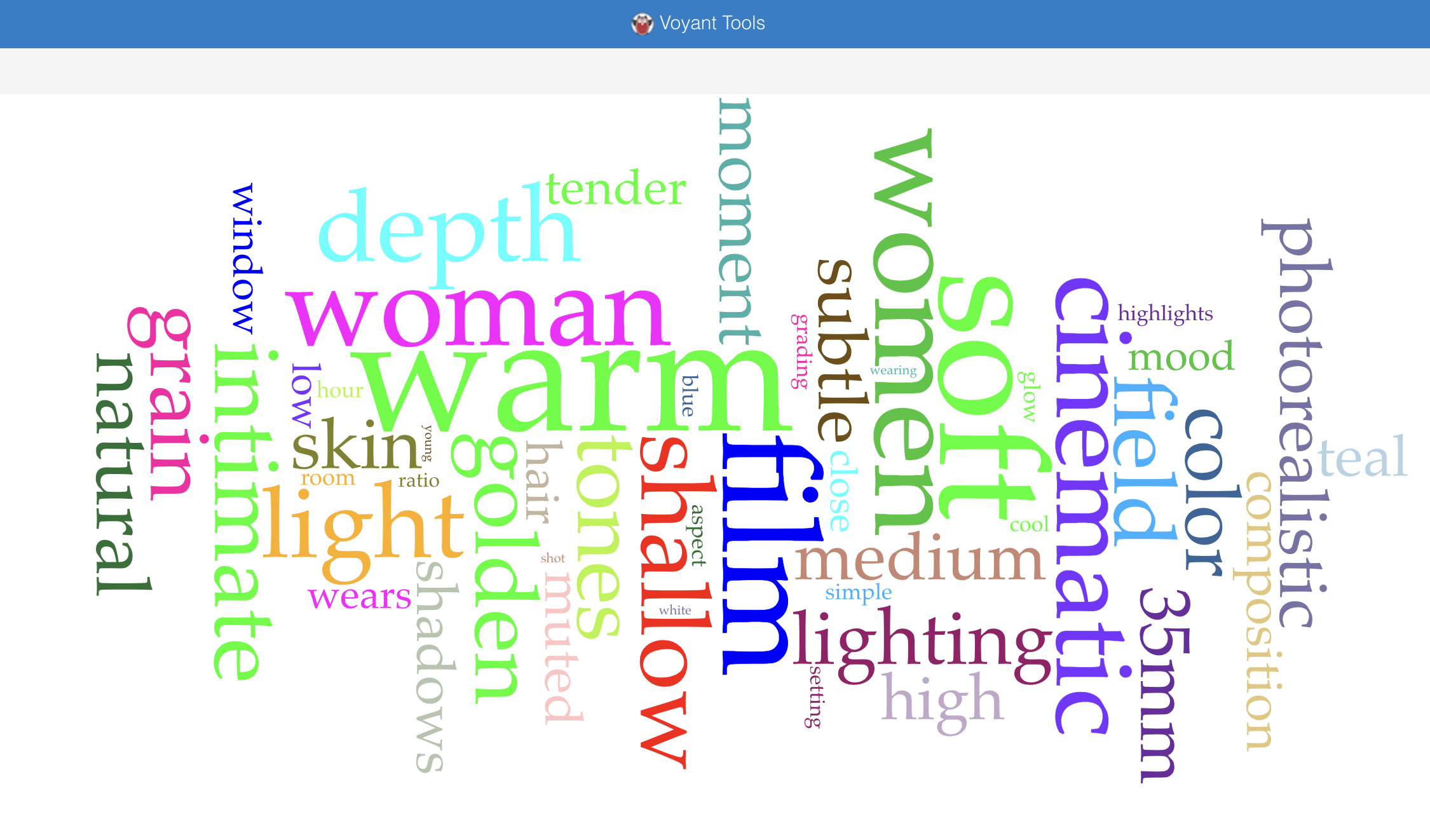
A word cloud showing GPT-5's most frequently occurring terms in the image description corpus.

A word tree of GPT-5's image description corpus showing occurrences and collocates of "warm."
Comparing the Image Outputs
When comparing the two models, we can observe that the rendering of atmosphere in the newer model relies increasingly on lighting and color and less on the composition of the landscape. Both models produce homogeneity in the overall corpus of associated images, albeit located in different aspects of illustration.
Looking at the associated image outputs, we can see that a consistent focus on meticulously rendered backgrounds gives way to more abstract mood lighting in several of the images.


What remains the same is the relative homogeneity of composition (largely a default) and the depiction of humans in both image sets. While the humans represented do shift from Dall-E's high-gloss hotness to something more realistic, diversity is confined to a selected number of hairstyles.